Building a Trustworthy A/B Testing Platform — Practical Guide and an Architecture Demonstration

Over the past two decades, along with the quick growth of the e-commerce, the digital versions of A/B tests and their generalizations have been more and more widely used for collecting user-generated data to test and improve internet based products and services [1].
While it has become one of the most important ways to gain business insights and make better decision, A/B tests and their generalizations have pitfalls and challenges [2–5]. It is important to understand how to design and implement a platform that serves trustworthy A/B tests. In this article, I am going to summarize the practical guide on the architecture design and implementation for A/B testing platform based on several important references [5–9], especially the seminal book [5] and paper [6] written by Ron Kohavi and his collaborators. As an application demonstration of the practical guide, an example architecture design together with some related sample code are described and discussed.
1. Trustworthy A/B Testing Platform — Practical Guide
Getting numbers is easy, getting numbers you can trust is quite difficult [2].
In general, architecture of a typical A/B testing service involves three components [6], randomization algorithm which randomly maps every end user to one of the variants of the test, assignment method which uses the output of the randomization algorithm to determine the experience that the corresponding end users will see on the website, and data path which captures the raw observation data as the users interact with the website, and possibly also processes it and helps generate reports of the test results.
Figure 1. below illustrates a possible A/B testing service platform architecture. The components randomization algorithm and assignment method comprise the core of the Variant Assignment Service, and the component data path corresponds to the Logs and Test Analysis Pipeline.
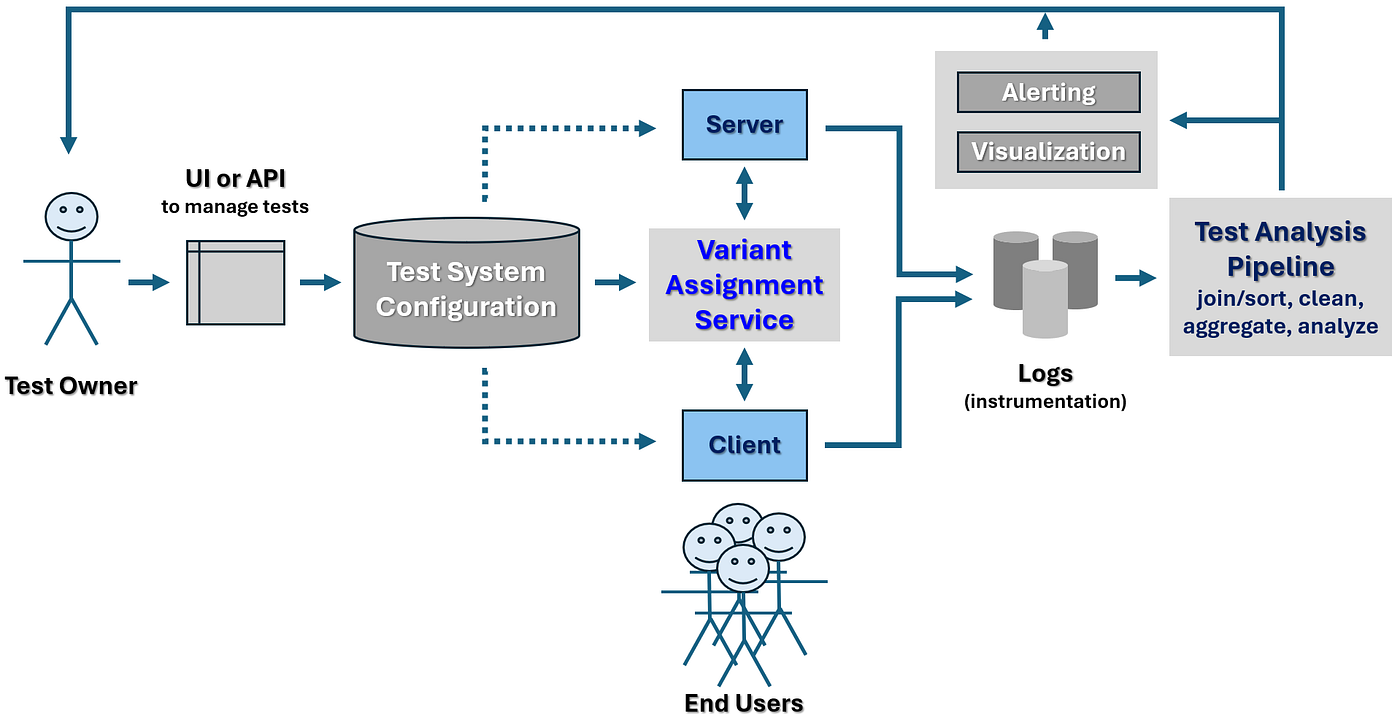
In this article, I will focus on the first two components, and leave the third component for elsewhere.
1.1 Randomization Algorithm
For an A/B testing platform, it is critical to make sure a good randomization algorithm is used. A good randomization algorithm must meet the following three conditions [6]:
- There is no bias toward any particular variant. In other words, with a 50–50 split for example, end users must be equally likely to see every variant of the test.
- Randomization algorithm results of specific user in the same test must be consistent. In other words, the same end user should always be mapped to the same variant, if they visit the site for multiple times during the test.
- When multiple (different) tests are run in parallel or sequentially, there must be no correlation between tests, unless it is intended.
So far, two types of randomization algorithms are typically used in different A/B testing platforms. One is pseudorandom with caching, for convenience, we call it PwC method. The other is hash and partition, for simplicity, we call it HP method.
1.1.1 Pseudorandom with Caching (PwC) Method
With the PwC method, a pseudorandom number generator is used in combination with some form of caching. For every end user, a pseudorandom number is generated and associated with the user. A good pseudorandom number generator usually satisfies the first and third conditions [6]. Once the number is generated and assigned to an end user, the assignment is cached, such that when the user re-visit the site later, the same random number will be used, instead of generating a new (different) one.
Kohavi et al. [6] verified that the random number generators built in popular languages work well as long as the generator is seeded only once at server startup.
Caching can be implemented either on server side (by storing assignments of all users in database), or on the client side (by storing a user’s assignment in a cookie) [5–6].
While the PwC method can fulfill the three conditions, it has several drawbacks. In addition to the ones Kohavi et al. discussed in [6], for us, one major issue the PwC method has is the requirement “as long as the generator is seeded only once at server startup”. In some cases, we may need to keep user assignments consistent in two or more different tests. Clearly, seeding the generator for each test is not an option as explained above. Reusing the cached user assignments from one of the tests is not applicable either, especially for the tests running in parallel. Consequently, to make sure the platform can cover as many use cases as possible, in the demonstration we will not use this method.
1.1.2 Hash and Partition (HP) Method
With the HP method, every user is assigned with a single unique user ID. Then using a hash function, the user ID (usually combined with some other information, such as test ID, or simply some random value etc.) is mapped to an integer that is uniformly distributed on a range of values. Then the range is partitioned, and each corresponding to a variant of the test.
Kohavi et al. [6] tested several popular hash functions, and found that (1). only the cryptographic hash function MD5 generated no correlations between experiments, (2). the cryptographic hash function SHA256 came close, which requires a five-way interaction to produce a correlation, and (3). other hash functions failed to pass even a two-way interaction test.
The major limitation of the HP method is the running-time performance of the cryptographic hash functions [6]. In our case, the running-time performance of the cryptographic hash functions is acceptable.
Comparisons among different cryptographic hash functions have been reported recently (see for example [10–12]). The results suggest that both MD5 and SHA256/SHA512 have the same (linear) complexity, the running time of MD5 is faster than SHA256/SHA512, and SHA256/SHA512 is more secure than MD5. The screenshots attached below (Figure 2.a and 2.b) are the profiling results for both time and memory use executed on my personal (Dell, Windows) laptop.


In our case, the performance differences between MD5 and SHA256/SHA512 as demonstrated above are neglectable. Accordingly, we choose the more secure SHA256/SHA512 algorithms in the demonstration.
1.2 Assignment Method
The assignment method is responsible for mapping different end users to the corresponding code path that exposes related website UI design option or executes related backend algorithm based on the randomization algorithm results.
Roughly speaking, depending on where the experiment changes are made, platforms can be divided into client-side experiment platform and server-side experiment platform [5]. Independent of the platform types, the variant assignment service can be implemented in two different ways, a standalone service on a dedicated server or a shared library that can be incorporated into the client or server directly. Which implementation to choose depends on both the use case and assignment method to be used.
Kohavi et al. [6] described four different assignment methods. Next a summary of the four methods is provided.
- Traffic Splitting

Traffic splitting method implements each variant on a different logical fleet of servers. With this method, no changes to existing code are required. Its major drawback is that it needs to set up and configure parallel fleets, which is usually expensive. Hence this method is recommended for testing changes with significantly different code.
- Page Rewriting
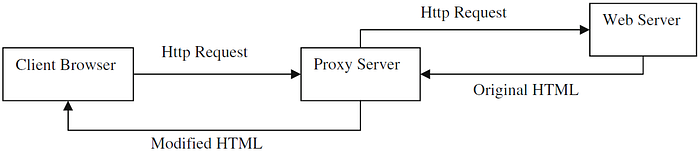
Similar to traffic splitting method, a proxy server is added in front of the web server too. Different from the traffic splitting method, page rewriting modifies the HTML content before it is presented to the end user, depending on the treatment group(s) of the experiment(s) the end user is randomly assigned to. This method does not involve changes in existing code either. Its major disadvantages are development and testing of variant content is more difficult and error-prone and testing backend algorithm is also difficult. Accordingly, it is not suitable for testing back-end changes or platform migrations.
- Client-side Assignment

Client-side assignment method only involves changes in end user’s browser. To implement an experiment, developer only needs to insert JavaScript code at render time to instruct the end user’s browser to invoke an assignment service, then depending on the variant assignment to instruct the browser to dynamically modify the page being presented to the end user. The major limitation of this method is that it is difficult to be used on complex sites that rely on dynamic content. Therefore, this method is best for experiments on front-end content that is mainly static.
- Server-side Assignment

Server-side assignment method does two things to produce a different user experience for each variant. First, it inserts (variant assignment service) API call(s) into the website’s servers at the point where the website logic differs between variants. Second, it branches the process to a different code path depending on the variant assignment(s) returned from the API call(s). While being very intrusive is the major disadvantage of this method, it is an extremely general method, and it can be used to experiment any aspect of a page as well as any backend features including those does not touch the front end, and it is also completely transparent to end users.
To greatly reduce the cost of running experiments with this method due to its deep intrusive nature, the method can be integrated into a content management system, such that the experiments can be configured by changing metadata instead of code.
In the architecture design demonstration, the server-side assignment method is used.
2. Building a Trustworthy A/B Testing Platform — an Architecture Demonstration
In the above section 1, we have summarized the practical guide on architecture design and implementation. In this section, we present and discuss a sample architecture design together with some sample code.
2.1 A Sample Architecture Design
The flow diagram in Figure 4 illustrates the high level architecture design of a sample A/B testing service platform. As I have mentioned in section 1, this is a server-side experimentation platform, and the variant assignment service and the test management service are implemented as standalone services and put on dedicated servers. Treatments of the experiments are implemented via metadata integrated into the content management system. The test management service exposes the test management functionalities via APIs, such that it can be integrated with a UI for test owners to create and manage tests.
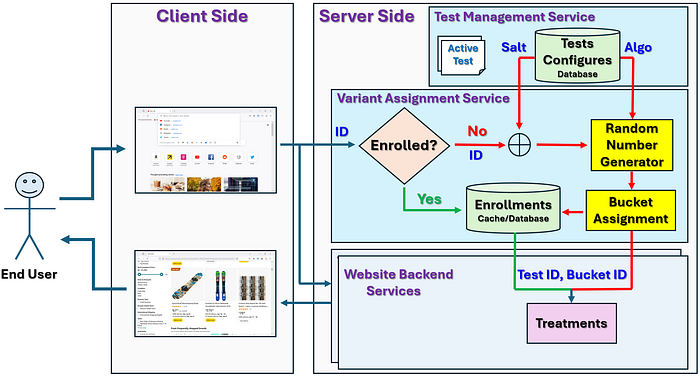
As one may have already noticed, on this experimentation platform, website user is chosen as both the randomization and analysis unit [5]. As in this article, we focus on the variant assignment and ignore the data path component, the analysis part is not included in the architecture design diagram.
Now lets go through the work flow of the experimentation platform before diving into the more detailed discussions on the variant assignment.
First step for a typical experiment is to design the test, which usually includes a statistical hypothesis, target user population, treatment details, etc. Here we assume that the test design has been reviewed and approved, and treatments have also implemented in the content management system. Accordingly, the second step is that the test owner create and schedule the test on the test management service. At this step, both a unique salt string and cryptographic hash algorithm will be selected and associated with the test (if the test owner didn’t choose, a random salt string will be automatically generated, and the default algorithm will be assigned).
When the test start date/time comes, the test will be automatically added into the active test list. During the time when the test is active, whenever a user visits the website, if this is their first time to visit the website, a unique id will be generated and assigned. With the user id, their enrollment history will be checked first, if they have enrolled in the test, their variant assignment will be retrieved, and sent to the website backend services to determine what treatment(s) to be applied for them. Otherwise, for each unenrolled active test, both the salt string and the hash algorithm associated with the test will be retrieved, and the salt string will be append to the user id string, then fed into the hash algorithm to get a random number. Using the generated random number, the user is assigned into one of the test buckets, and the (test id, bucket id) pair comprises the variant assignment of the user in the corresponding test. Once the variant assignment is derived, it will be passed to the website backend services to determine the treatment(s) to be applied.
2.2 Variant Assignment Service
In section 2.1, we have presented the high level architecture design of a sample A/B Testing service platform, and explained its work flow. In this section, I am going to focus on the variant assignment service, present and discuss some sample code.
The “standard” A/B tests usually split the target population into two buckets, each covers 50% of the target population. In practice, an A/B test may involve more buckets and uneven splitting. One typical example is that the controlled test will be executed on only a portion of the target population. For example, if the controlled test will be executed on half of the target population, then the bucket can be split as (50%, 25%, 25%). In addition to such “multi-level” test scenarios, A/B tests are also used for incremental rollout of the new features. In these cases, target population splitting such as (10%, 90%), (20%, 80%), etc. may be used.
Next, we explain how variant assignment algorithm works in the sample design.
Without loss of generality, we assume there are N buckets involved in a test, and percentage of each bucket is P_N. Accordingly, we have P_1 + P_2 + … + P_N = 100, and the buckets can be mapped onto the line segment [0, 100). Taking a test with two buckets, control and variation, each covers 50% of the target population, as example, the interval [0, 50) corresponds to the control bucket, and the interval [50, 100) corresponds to the variation bucket. Whenever a user visits the website, for specific test, the concatenation of the salt string and the user id string is passed to the selected cryptographic hash function to “generate” a random integer. Taking the modulo 100 on it, we get an integer between 0 and 100. The interval on the line segment the number falls in determines which bucket the user is assigned to. Figure 5. illustrates the bucket assignment of two users, with user ids as 1719192818611227629 and 1719192818610612723, respectively. Assume the salt string of the test is: ‘f9c8e87a2dd7498099dc430e4814e84b’, then feeding the concatenated strings ‘1719192818611227629f9c8e87a2dd7498099dc430e4814e84b’ and ‘1719192818610612723f9c8e87a2dd7498099dc430e4814e84b’ into the selected cryptographic hash function, say, sha256, we get 13 and 89 respectively. Accordingly, the two users are assigned to control bucket and variation bucket respectively.

The code snippet below demonstrates a sample implementation of the bucket assignment algorithm.
The snippet attached below demonstrates a highly simplified sample test metadata.
With the test metadata and the variant assignment implementation provided above, we are ready to enroll users into treatment groups specified in the test. Figure 6.a and 6.b shows the sample code for generating 100K user ids and enrolling them into the test and the cumulative enrollment counts for both control bucket and variation bucket respectively.


3. Conclusion
Over the past few decades, A/B tests and their generalizations have become one of the most important ways to gain business insights and make better decision. It is critical to understand how to design and implement a platform that serves trustworthy A/B tests. In this article, the practical guide on architecture design and implementation for A/B Testing service platform is summarized. To better demonstrate the application of the practical guide, high level architecture design of a sample A/B Testing platform is presented and explained. As the variant assignment is the core of the experimentation platform, some sample code is presented and discussed.
References
[1] R. Kohavi, and R. Longbotham. Online Controlled Experiments and A/B Tests. in Encyclopedia of Machine Learning and Data Mining, eds. D. Phung, G.I. Webb, and C. Sammut, pp 922–929, Jan 2017
[2] R. Kohavi, and R. Longbotham. Unexpected Results in Online Controlled Experiments. ACM SIGKDD Explorations Newsletters, vol 12(2): 31–35, Mar 2011
[3] Y. Xu, N. Chen, A. Fernandez, O. Sinno, and A. Bhasin. From Infrastructure to Culture: A/B Testing Challenges in Large Scale Social Networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 2227–2236, Aug 2015
[4] L. Lu, and C. Liu. Separation Strategies for Three Pitfalls in A/B Testing. In Proceedings of the 2nd KDD Workshop on User Engagement Optimization, UEO, pp 1–7, 2014
[5] R. Kohavi, D. Tang, and Y. Xu. Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing. Cambridge University Press, Cambridge, United Kingdom, 10.1017/9781108653985, Mar 2020
[6] R. Kohavi, R. Longbotham, D. Sommerfield, and R. M. Henne. Controlled Experiments on the Web: Survey and Practical Guide. Data Mining and Knowledge Discovery, vol 18(1): 140–181, July 2008
[7] D. Tang, A. Agarwal, D. O’Brien, and M. Meyer. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. KDD’10: Proceedings 16th Conference on Knowledge Discovery and Data Mining, pp 17–26, July 2010
[8] E. Bakshy, D. Eckles, and M.S. Bernstein. Designing and Deploying Online Field Experiments. WWW’14: Proceedings of the 23rd International Conference on World Wide Web. pp 283–292, Apr 2014
[9] R. Kohavi, A. Deng, B. Frasca, T. Walker, Y. Xu, and N. Pohlmann. Online Controlled Experiments at Large Scale. KDD’13: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp 1168–1176, Aug 2013
[10] D. Rachmawati, J.T. Tarigan, and A.B.C Ginting. A Comparative Study of Message Digest 5 (MD5) and SHA256 Algorithm. J. Phys.: Conf. Ser. 978 012116, 2018
[11] S. Aggarwal, N. Goyal, and K. Aggarwal. A Review of Comparative Study of MD5 and SHA Security Algorithm. International Journal of Computer Applications (0975–8887), vol 104(14): 1–4, Oct 2014
[12] S. Long. A Comparative Analysis of the Application of Hashing Encryption Algorithms for MD5, SHA-1, and SHA-512. J. Phys.: Conf. Ser. 1314 012210, 2019
